· 15 minute read

Pandas: How to Read Data From HTML Tables
· · 8 minute read
Introduction
When you start a new data science project, you’ll first need a relevant dataset.
Suppose you find a web page containing such data in table format. How can you use this data for your project?1
This article shows you how to:
- Parse web pages and read table data using Pandas and Python.
- Clean up the extracted data and save it in a CSV file.
- Handle a typical error you may encounter when scraping web pages.
- Convert DataFrame to an HTML table.
Install Required Libraries
We’ll parse web pages using Pandas’ method read_html(). This method internally uses the below libraries to read the web page:
We’ll also need the Requests library for customizing HTTP requests.
You can install all of these Python libraries using pip commands:
## Run below from the command line
pip install lxml
pip install html5lib
pip install BeautifulSoup4
pip install requestsUse read_html() to Parse Webpage
Let’s say you want to compile the list of fastest marathon runners.
A quick Google search takes you to a web page on Runner’s World. The page contains HTML tables with the fastest marathon records across different categories.
We are interested in the first two tables that show the 10 fastest men and women runners:
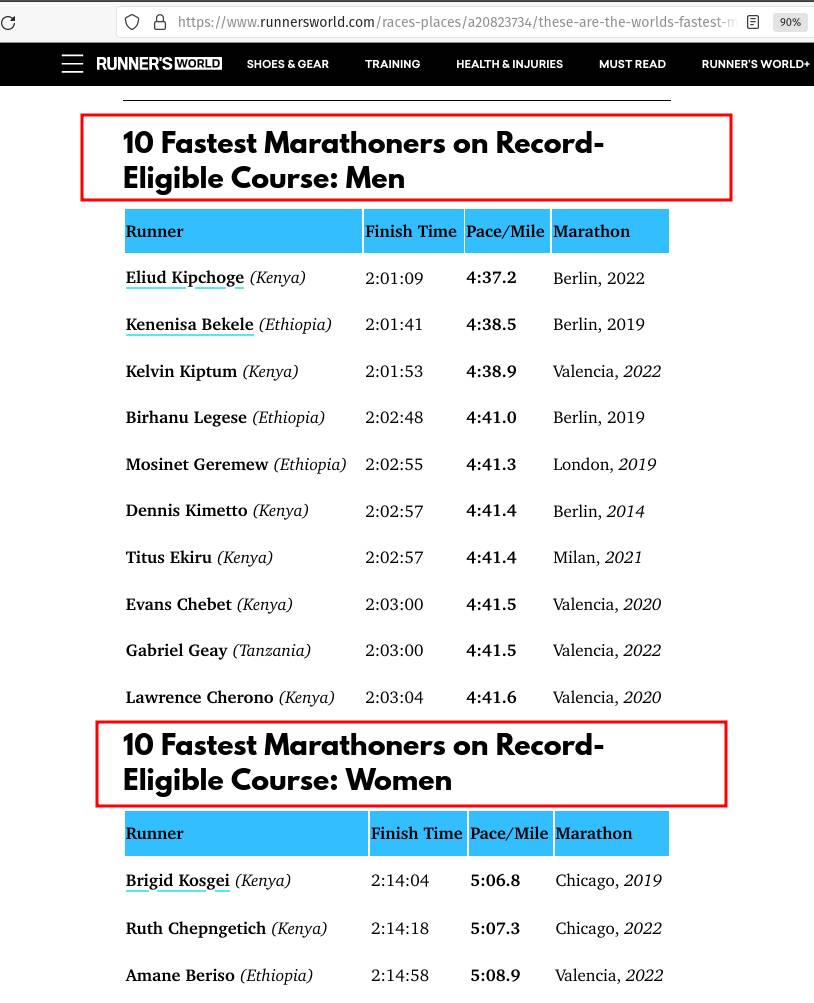
We’ll use the Pandas’ method read_html() to parse the webpage. This method returns a list of DataFrames, one for each HTML table on the page.
The first row in each HTML table contains the column headers (Runner, Finish Time, ..). So we’ll set the parameter header=0 when invoking read_html():
import pandas as pd
# URL of the webpage containing marathon records
DATA_URL = 'https://www.runnersworld.com/races-places/a20823734/these-are-the-worlds-fastest-marathoners-and-marathon-courses/'
# Parse all the HTML tables and return a list of DataFrames
# First row contains column headers. Thus header=0
html_tables = pd.read_html(DATA_URL, header=0)
# Check data type and size for the returned value
print(f'TYPE: {type(html_tables)}, SIZE: {len(html_tables)}')TYPE: <class 'list'>, SIZE: 8The method read_html() returned a list of eight DataFrames. That’s because the web page contained eight HTML tables.
Fastest Marathoners - Men
The first DataFrame from the list contains the 10 fastest marathoners:
# First table from the web page - fastest men
fastest_men = html_tables[0]
# Print data type
print(type(fastest_men))
# Print the content of the DataFrame
fastest_menpandas.core.frame.DataFrame| Runner | Finish Time | Pace/Mile | Marathon | |
|---|---|---|---|---|
| 0 | Eliud Kipchoge (Kenya) | 2:01:09 | 4:37.2 | Berlin, 2022 |
| 1 | Kenenisa Bekele (Ethiopia) | 2:01:41 | 4:38.5 | Berlin, 2019 |
| 2 | Kelvin Kiptum (Kenya) | 2:01:53 | 4:38.9 | Valencia, 2022 |
| 3 | Birhanu Legese (Ethiopia) | 2:02:48 | 4:41.0 | Berlin, 2019 |
| 4 | Mosinet Geremew (Ethiopia) | 2:02:55 | 4:41.3 | London, 2019 |
| 5 | Dennis Kimetto (Kenya) | 2:02:57 | 4:41.4 | Berlin, 2014 |
| 6 | Titus Ekiru (Kenya) | 2:02:57 | 4:41.4 | Milan, 2021 |
| 7 | Evans Chebet (Kenya) | 2:03:00 | 4:41.5 | Valencia, 2020 |
| 8 | Gabriel Geay (Tanzania) | 2:03:00 | 4:41.5 | Valencia, 2022 |
| 9 | Lawrence Cherono (Kenya) | 2:03:04 | 4:41.6 | Valencia, 2020 |
The DataFrame fastest_men contains the same data as the first HTML table from the webpage.
We can store this DataFrame for future use. Let’s use the method to_csv() to save it in a CSV file:
# Save the DataFrame to a CSV file.
# Dont save the index (index=False)
fastest_men.to_csv('fastest_men.csv', index=False)You should now see the file fastest_men.csv in your current directory.
Fastest Marathoners - Women
Recall that the read_html() method returned html_tables, a list of DataFrames containing data from all the tables on the web page.
The second table contained the fastest female marathon runners. Let’s look at the corresponding DataFrame:
# Second DataFrame in the list contains fastest female runners
fastest_women = html_tables[1]
fastest_women| Runner | Finish Time | Pace/Mile | Marathon | |
|---|---|---|---|---|
| 0 | Brigid Kosgei (Kenya) | 2:14:04 | 5:06.8 | Chicago, 2019 |
| 1 | NaN | NaN | NaN | NaN |
| 2 | Ruth Chepngetich (Kenya) | 2:14:18 | 5:07.3 | Chicago, 2022 |
| 3 | Amane Beriso (Ethiopia) | 2:14:58 | 5:08.9 | Valencia, 2022 |
| 4 | Paula Radcliffe (Great Britain) | 2:15:25 | 5:09.9 | London, 2003 |
| 5 | Tigist Assefa (Ethiopia) | 2:15:37 | 5:10.3 | Berlin, 2022 |
| 6 | Rosemary Wanjiru (Kenya) | 2:16:28 | 5:12.3 | Tokyo, 2023 |
| 7 | Letesenbet Gidey (Ethiopia) | 2:16:49 | 5:13.1 | Valencia, 2022 |
| 8 | Tsehay Gemechu (Ethiopia) | 2:16:56 | 5:13.4 | Tokyo, 2023 |
| 9 | Mary Keitany (Kenya) | 2:17:01 | 5:13.6 | London, 2017 |
| 10 | Peres Jepchirchir (Kenya) | 2:17:16 | 5:14.1 | Valencia, 2020 |
| 11 | NaN | NaN | NaN | NaN |
There are two rows with missing data (NaN). Let’s use the DataFrame method dropna() to remove these rows:
# remove rows (axis='index) with missing values
# in all the columns (how='all')
fastest_women = fastest_women.dropna(axis='index', how='all')
fastest_women| Runner | Finish Time | Pace/Mile | Marathon | |
|---|---|---|---|---|
| 0 | Brigid Kosgei (Kenya) | 2:14:04 | 5:06.8 | Chicago, 2019 |
| 2 | Ruth Chepngetich (Kenya) | 2:14:18 | 5:07.3 | Chicago, 2022 |
| 3 | Amane Beriso (Ethiopia) | 2:14:58 | 5:08.9 | Valencia, 2022 |
| 4 | Paula Radcliffe (Great Britain) | 2:15:25 | 5:09.9 | London, 2003 |
| 5 | Tigist Assefa (Ethiopia) | 2:15:37 | 5:10.3 | Berlin, 2022 |
| 6 | Rosemary Wanjiru (Kenya) | 2:16:28 | 5:12.3 | Tokyo, 2023 |
| 7 | Letesenbet Gidey (Ethiopia) | 2:16:49 | 5:13.1 | Valencia, 2022 |
| 8 | Tsehay Gemechu (Ethiopia) | 2:16:56 | 5:13.4 | Tokyo, 2023 |
| 9 | Mary Keitany (Kenya) | 2:17:01 | 5:13.6 | London, 2017 |
| 10 | Peres Jepchirchir (Kenya) | 2:17:16 | 5:14.1 | Valencia, 2020 |
The DataFrame looks good. Let’s save it to a CSV file as well using to_csv():
# Save DataFrame to CSV file
# Don't save index (index=False)
fastest_women.to_csv('fastest_women.csv', index=False)Handle 403 Error
Sometimes you’ll run into an HTTP 403 error when reading an HTML page. Let’s see this in action.
Suppose you’re in the market for a road bike. You come across a page on cyclingtips.com that lists the top 20 fastest bikes. When you use read_html() to get the list as a DataFrame, you’ll see an HTTP 403 error:
DATA_URL = 'https://www.cyclingtips.com/2020/04/the-top-20-fastest-road-bikes-in-the-world-according-to-strava/'
pd.read_html(DATA_URL)HTTPError: HTTP Error 403: Forbidden.
Why did this happen?
The website expects the request to originate from a browser. Since read_html() is trying to read the page programmatically, it responds back with the 403 error.
You can resolve this issue by setting the User-Agent header in the request:
# We'll need requests library for this
import requests
# Prepare a dictionary with the User-Agent header
# and its value (UA string for Firefox)
request_headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/111.0'
}
# Use requests.get() to read the webpage.
# Pass the headers dictionary
response = requests.get(DATA_URL, headers=request_headers)
# Now use Pandas read_html()
# Pass the page HTML (response.text) as input
html_tables = pd.read_html(response.text, index_col=0)
# The first table is what we wanted
fastest_bikes = html_tables[0]
fastest_bikes| Bike | Median speed (km/h) |
Median speed (mph) |
Similar models and median (km/h) |
|
|---|---|---|---|---|
| Ranking | ||||
| 1 | Canyon Aeroad CF SLX | 25.3 | 15.7 | Canyon Aeroad (same speed) |
| 2 | Ridley Noah SL | 25.1 | 15.6 | Ridley Noah – 24.6 km/h |
| 3 | Specialized S-Works Venge | 25.0 | 15.5 | Venge Pro – 24.8, Venge – 24.8, S-Works Venge ... |
| 4 | Sensa Romagna | 25.0 | 15.5 | NaN |
| 5 | Orbea Orca Aero | 24.9 | 15.5 | NaN |
| ... | ... | ... | ... | ... |
| 16 | Giant TCR Advanced Pro 1 | 24.2 | 15.0 | Giant TCR Advanced SL – 23.9 |
| 17 | Argon 18 Gallium Pro | 24.1 | 15.0 | NaN |
| 18 | Pinarello F10 | 24.0 | 14.9 | NaN |
| 19 | Bianchi Aria | 23.9 | 14.9 | NaN |
| 20 | Bianchi Oltre XR4 | 23.9 | 14.9 | NaN |
20 rows × 4 columns
Awesome! We fixed the 403 error and successfully loaded the HTML table into a DataFrame.
Convert DataFrame to HTML Table
So far, we’ve parsed web pages and extracted tables as DataFrames. What if you want to do the opposite?
Let me show you how to convert a DataFrame into an HTML table.
The below code creates a DataFrame containing the five fastest 100 meters runners. It shows their rank, name, finish time (in seconds), and country:
# Fastest 100 meters runners
fastest_100m = pd.DataFrame({
'Rank': range(1, 6),
'Runner': ['Usain Bolt', 'Tyson Gay', 'Yohan Blake', 'Asafa Powell', 'Justin Gatlin'],
'Time': [9.58, 9.69, 9.69, 9.72, 9.74], # seconds
'Country': ['Jamaica', 'USA', 'Jamaica', 'Jamaica', 'USA']
})
fastest_100m = fastest_100m.set_index('Rank')
fastest_100m| Runner | Time | Country | |
|---|---|---|---|
| Rank | |||
| 1 | Usain Bolt | 9.58 | Jamaica |
| 2 | Tyson Gay | 9.69 | USA |
| 3 | Yohan Blake | 9.69 | Jamaica |
| 4 | Asafa Powell | 9.72 | Jamaica |
| 5 | Justin Gatlin | 9.74 | USA |
The DataFrame method to_html() will return the content formatted as HTML code. You can use this code to render the DataFrame on any web page.
# Convert DataFrame to an HTML table
fastest_100m.to_html()'<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th><th>Runner</th><th>Time</th><th>Country</th>
</tr>
<tr>
<th>Rank</th><th></th><th></th><th></th>
</tr>
</thead>
<tbody>
<tr>
<th>1</th><td>Usain Bolt</td><td>9.58</td><td>Jamaica</td>
</tr>
<tr>
<th>2</th><td>Tyson Gay</td><td>9.69</td><td>USA</td>
</tr>
<tr>
<th>3</th><td>Yohan Blake</td><td>9.69</td><td>Jamaica</td>
</tr>
<tr>
<th>4</th><td>Asafa Powell</td><td>9.72</td><td>Jamaica</td>
</tr>
<tr>
<th>5</th><td>Justin Gatlin</td><td>9.74</td><td>USA</td>
</tr>
</tbody>
</table>'Summary
This tutorial showed you how to source data from web pages. Let’s recap the practical skills you learned today:
- Use the Pandas method read_html() to parse HTML tables from a web page.
- Save the extracted DataFrames as CSV files using the to_csv() method.
- Fix HTTP 403 error while parsing a web page.
- Use the method to_html() to convert DataFrames into HTML tables.
Footnotes
-
Please read the terms and conditions of the website to check whether it allows web scraping. That’s especially true if you plan to use their data for commercial purposes. ↩
Title Image by
Pexels