· 15 minute read

Pandas: How to Read and Write Data to a SQL Database
· · 9 minute read
Introduction
We recently covered the basics of Pandas and how to use it with Excel files.
Today, you’ll learn to read and write data to a relational SQL database using Python and Pandas. By the end of this article, you’ll know how to:
- Connect to a SQL database using SQLAlchemy.
- Write DataFrame to a database table:
- Create a table if it doesn’t exist.
- Append to an existing table.
- Read an entire database table into a DataFrame.
- Load results of a SQL query into a DataFrame.
- Use SQL query with parameters to populate a DataFrame.
Let’s get started!
Local Environment Setup
Please follow the steps in this section if you want to code along with this tutorial.
Install MySQL and Workbench
Pandas can work with a variety of databases (Postgresql, Oracle, MS-SQL, etc.). We’ll use MySQL in this tutorial.
You can install MySQL by following the steps outlined in this YouTube video. It’ll also install Workbench, a visual tool to run queries against MySQL database.
Create Test Database
Let’s create a new database, test_db, using the MySQL command-line client. We’ll run all our SQL operations against this database.
# Launch mysql command line client
# Enter your mysql root password when prompted
~$ mysql -u root -p
Enter password:
mysql> CREATE DATABASE test_db;
mysql> quit
ByeInstall SQLAlchemy and MySQL Driver
Pandas uses SQLAlchemy, a popular Python library, to interact with SQL databases. SQLAlchemy, in turn, will need a database driver to connect to MySQL.
You can install them using the below pip commands:
## Run below from the command line
# install sqlalchemy
pip install SQLAlchemy
# install mysql driver
pip install mysql-connector-pythonCreate Database ‘Engine’
Now that our MySQL database setup is done, how do we connect to it?
SQLAlchemy requires us first to create a database engine. Then we can use this engine to get database connections whenever we want to run SQL queries.
Belode code uses SQLAlchemy’s create_engine() to get a new database engine:
# Import the create_engine method
from sqlalchemy import create_engine
# The database URL must be in a specific format
db_url = "mysql+mysqlconnector://{USER}:{PWD}@{HOST}/{DBNAME}"
# Replace the values below with your own
# DB username, password, host and database name
db_url = db_url.format(
USER = "root",
PWD = "<ROOT_PASSWORD>",
HOST = "localhost:3306",
DBNAME = "test_db"
)
# Create the DB engine instance. We'll use
# this engine to connect to the database
engine = create_engine(db_url, echo=False)Now our database is ready, and we have a way to connect to it. Let’s perform some operations against it.
Prepare Pandas DataFrame
Suppose you’ve compiled the list of the five largest cities in the world.1 You also gathered some additional details about them:
# Five most populated cities in the world
cities = ['Tokyo', 'Delhi', 'Shanghai',
'São Paulo', 'Mexico City']
# and their countries
countries = ['Japan', 'India', 'China',
'Brazil', 'Mexico']
# the continents they are located in
continents = ['Asia', 'Asia', 'Asia',
'North America', 'South America']
# and their populations
population = [37468000, 28514000, 25582000,
21650000, 21581000]Let’s store this information in a tabular form as a Pandas DataFrame:
# Load pandas
import pandas as pd
# Create Pandas DataFrame
largest_cities_df = pd.DataFrame({
"City": cities,
"Country": countries,
"Continent": continents,
"Population": population
})
# Print the DataFrame
largest_cities_df| City | Country | Continent | Population | |
|---|---|---|---|---|
| 0 | Tokyo | Japan | Asia | 37468000 |
| 1 | Delhi | India | Asia | 28514000 |
| 2 | Shanghai | China | Asia | 25582000 |
| 3 | São Paulo | Brazil | North America | 21650000 |
| 4 | Mexico City | Mexico | South America | 21581000 |
We want to store this information in our MySQL database. How do we do that?
Write DataFrame to New Table
The DataFrame method to_sql() writes all the rows to a database table. You can specify the name of the table using the name parameter.
By default, to_sql() assumes that the table doesn’t exist. So it will create the table.
The below code uses the engine’s begin() method to create a database connection. Then it invokes the DataFrame method to_sql(). That’ll create the table largest_cities and insert all the DataFrame rows into the table:
# Use engine.begin() to create database connection.
# Set it as the context manager. That'll ensure
# the connection is automatically closed
# after SQL operation is done
with engine.begin() as conn:
# Invoke DataFrame method to_sql() to
# create the table 'largest_cities' and
# insert all the DataFrame rows into it
largest_cities_df.to_sql(
name='largest_cities', # database table
con=conn, # database connection
index=False # Don't save index
)
Let’s confirm by querying the database using Workbench:
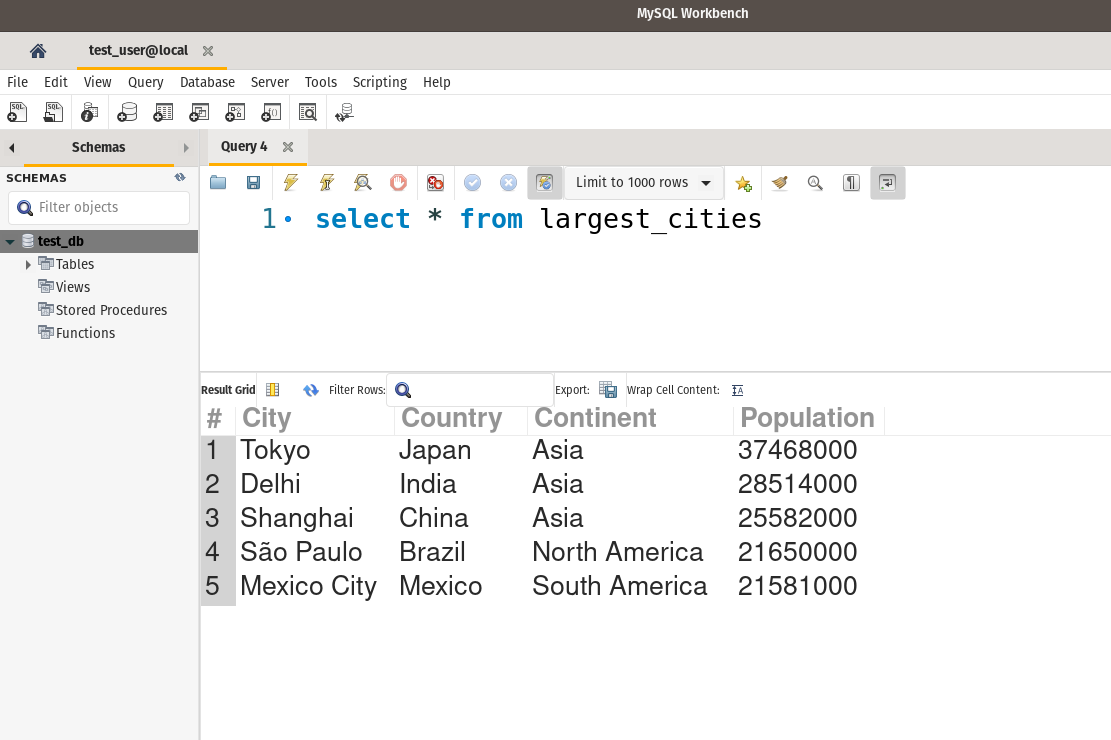
Indeed, the table largest_cities now exists and contains the same data as our DataFrame object.
Append DataFrame to Existing Table
Let’s say you gather data for the next five most populous cities (ranked 5-10). And you store it in the DataFrame largest_cities_df2:
# Next 5 most populated cities
cities2 = ['Cairo', 'Mumbai', 'Beijing',
'Dhaka','Osaka']
# their countries
countries2 = ['Egypt', 'India', 'China',
'Bangladesh', 'Japan']
# the continents they are located in
continents2 = ['Africa', 'Asia', 'Asia',
'Asia', 'Asia']
# and their populations
population2 = [20076000, 19980000, 19618000,
19578000, 19281000]
# Create Pandas DataFrame. It has the same columns
# labels as the first DataFrame
largest_cities_df2 = pd.DataFrame({
"City": cities2,
"Country": countries2,
"Continent": continents2,
"Population": population2
})
# print DataFrame
largest_cities_df2| City | Country | Continent | Population | |
|---|---|---|---|---|
| 0 | Cairo | Egypt | Africa | 20076000 |
| 1 | Mumbai | India | Asia | 19980000 |
| 2 | Beijing | China | Asia | 19618000 |
| 3 | Dhaka | Bangladesh | Asia | 19578000 |
| 4 | Osaka | Japan | Asia | 19281000 |
Suppose you want to insert this data into the existing table largest_cities.
Can you use the DataFrame method to_sql() as we did in the last section? Let’s invoke it on largest_cities_df2 and see what happens:
# This will throw error:
# ValueError: Table 'largest_cities' already exists.
with engine.begin() as conn:
largest_cities_df2.to_sql(name='largest_cities', con=conn, index=False)ValueError: Table ‘largest_cities’ already exists.
As mentioned earlier, to_sql() will try to create the database table by default. And it’ll throw an error if the table already exists.
You can change this behavior using the parameter if_exists. Since we want to insert entries in the existing table, we’ll set this parameter to append:
with engine.begin() as conn:
largest_cities_df2.to_sql(
name='largest_cities',
# insert values into an existing table
if_exists='append',
con=conn,
index=False
)Let’s confirm by running the select query in Workbench:
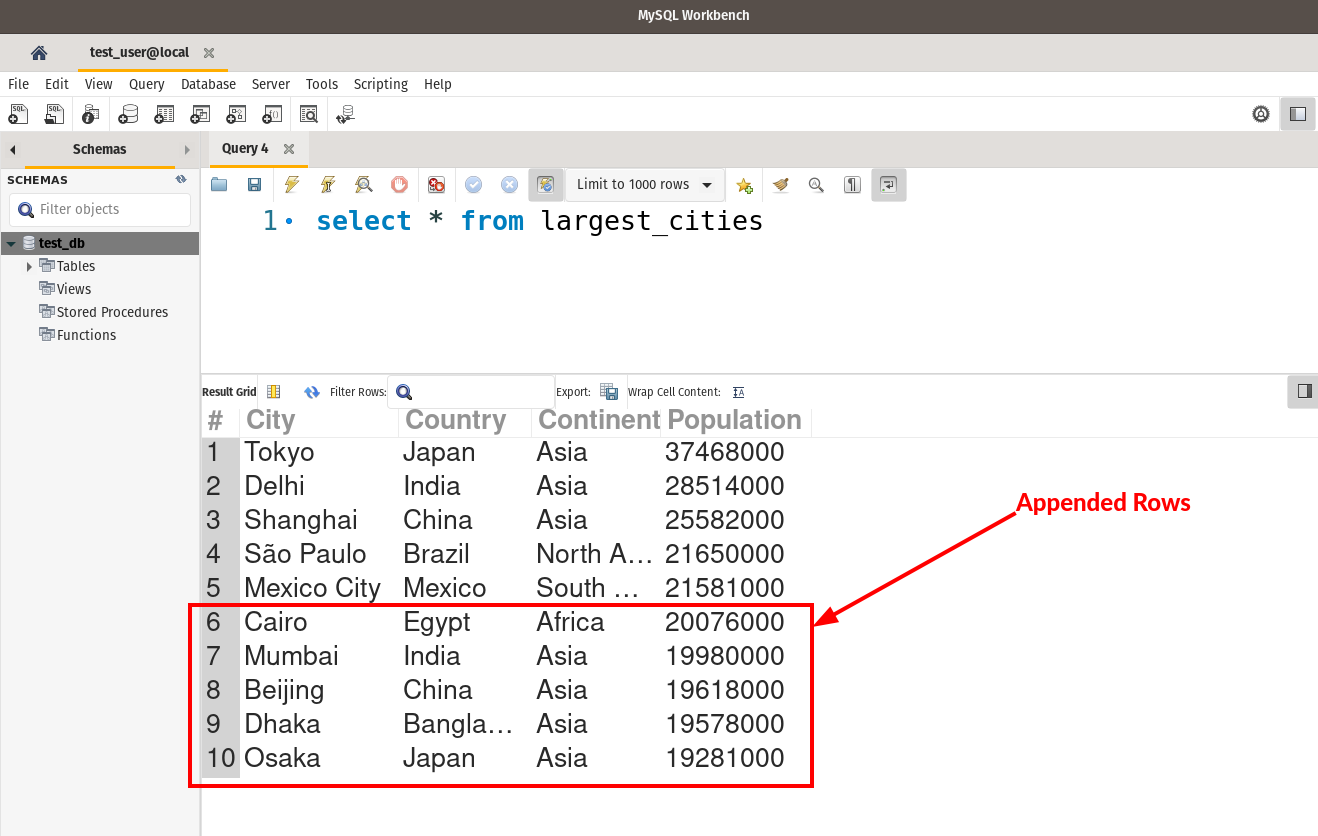
Looks good. We can see the newly inserted rows (red box).
A word of caution:
If you set the parameter if_exists to
replace, pandas will drop the existing table and create a new one. That is extremely dangerous as you’ll lose the current data in the table. Therefore use if_exists=‘replace’ with utmost caution!
Load Full Table
You can read an entire database table into a DataFrame using the method read_sql_table(). Set the parameter table_name to the table you want to load.
The below code reads all the rows from the table largest_cities. It also sets the column City as the index using the parameter index_col :
with engine.begin() as conn:
# Load all the rows from the table
# 'largest_cities' into pandas DataFrame
largest_cities_db = pd.read_sql_table(
table_name='largest_cities',
con=conn,
# Set the column 'City' as the index
index_col='City'
)
# print the DataFrame
largest_cities_db| Country | Continent | Population | |
|---|---|---|---|
| City | |||
| Tokyo | Japan | Asia | 37468000 |
| Delhi | India | Asia | 28514000 |
| Shanghai | China | Asia | 25582000 |
| São Paulo | Brazil | North America | 21650000 |
| Mexico City | Mexico | South America | 21581000 |
| Cairo | Egypt | Africa | 20076000 |
| Mumbai | India | Asia | 19980000 |
| Beijing | China | Asia | 19618000 |
| Dhaka | Bangladesh | Asia | 19578000 |
| Osaka | Japan | Asia | 19281000 |
Load SQL Query Results
We loaded the whole database table in the last section. But sometimes, you want to run a SQL query and load its results in a DataFrame. You can use the Pandas method read_sql_query() to do that.
For example, the following code uses read_sql_query() to find the number of cities per country in the largest_cities table:
from sqlalchemy import text
# Wrap the SQL query in SQLAlchemy text()
sql_query = text("""select Country, count(*) as Count
from test_db.largest_cities
group by Country
order by Count desc""")
# Execute the query and store result in
# the DataFrame 'country_count'
with engine.begin() as conn:
country_count = pd.read_sql_query(
sql=sql_query,
con=conn
)
# Print the DataFrame
country_count| Country | Count | |
|---|---|---|
| 0 | Japan | 2 |
| 1 | India | 2 |
| 2 | China | 2 |
| 3 | Brazil | 1 |
| 4 | Mexico | 1 |
| 5 | Egypt | 1 |
| 6 | Bangladesh | 1 |
SQL Query With Named Parameters
A parameterized SQL query is a query with placeholder parameters that you can populate when you execute the query. This allows you to reuse the same query with different parameter values.
Let me illustrate using an example.
The below query pulls the cities for a given country. Notice that the country is not hardcoded in the query. Instead, it uses the parameter in_country:
# Parameterized query
# parameters are specified using the colon ( : )
sql_with_param = text("""select * from largest_cities
where Country = :in_country""")Let’s execute this query to get cities for India. We’ll need to pass a dictionary with the parameter name and its value:
# dictionary containing parameter name value
input_param = {'in_country': 'India'}
with engine.begin() as conn:
country_cities = pd.read_sql_query(
sql=sql_with_param,
# Pass the parameters dictionary
params=input_param,
con=conn
)
# print the DataFrame containing results
# of the parameterized query
country_cities| City | Country | Continent | Population | |
|---|---|---|---|---|
| 0 | Delhi | India | Asia | 28514000 |
| 1 | Mumbai | India | Asia | 19980000 |
We can reuse the parameterized query to get cities for a different country.
The below code retrieves the cities for China. It uses the same query as above but passes a different parameter value:
# Get cities for China
input_param = {'in_country': 'China'}
with engine.begin() as conn:
country_cities = pd.read_sql_query(
sql=sql_with_param,
params=input_param,
con=conn
)
# Print DataFrame containing SQL results
country_cities| City | Country | Continent | Population | |
|---|---|---|---|---|
| 0 | Shanghai | China | Asia | 25582000 |
| 1 | Beijing | China | Asia | 19618000 |
Multiple named parameters
You can prepare SQLs with more than one parameter as well. For example, the below query has two parameters - in_continent and in_population:
sql_with_params = text("""select * from largest_cities
where Continent = :in_continent
and population > :in_population""")When executing this query, you’ll need to pass a dictionary containing values for both parameters:
# Get cities from Asia with
# minimum population of 20 million
input_params = {
'in_continent': 'Asia',
'in_population': 20000000
}
with engine.begin() as conn:
filtered_cities = pd.read_sql_query(
sql=sql_with_params,
params=input_params,
con=conn
)
# Print DataFrame containing SQL results
filtered_cities| City | Country | Continent | Population | |
|---|---|---|---|---|
| 0 | Tokyo | Japan | Asia | 37468000 |
| 1 | Delhi | India | Asia | 28514000 |
| 2 | Shanghai | China | Asia | 25582000 |
Summary
This tutorial showed you how to interact with a SQL database using Pandas and Python. Let’s recap the practical skills you picked up today:
- Use SQLAlchemy to connect to a SQL data database (specifically MySQL).
- Write a DataFrame to a database table using the method to_sql():
- Create a new table and insert data.
- Append data to an existing table with the parameter if_exists.
- Load the full table into a DataFrame using read_sql_table().
- Read results of a SQL query into a DataFrame using read_sql_query().
- Use named parameters when executing SQL queries.
Footnotes
-
Data Source: 30 Largest Cities in the World - ThoughtCo. ↩
Title Image by
sofi5t