· 10 minute read

How to Slice Pandas DataFrames Using iloc and loc
· · 15 minute read
Introduction
I recently covered the basics of Pandas and how it integrates with Excel Spreadsheets and SQL databases.
Today, I’ll teach you how to select data from a Pandas DataFrame. Specifically, you’ll learn how to use DataFrame’s row and column index to extract data from it.
Here’s what we’ll cover:
- Review two types of DataFrame indexes - label and (numeric) position-based.
- How to use Pandas methods1 loc[] and iloc[] to select data using these indexes.
- How to fetch data for
- Specific index values.
- List of index values.
- Range of index values (using the Python slice notation).
- Combinations of the above approaches.
I want to ensure that you gain hands-on skills you can immediately use in your projects. So, you’ll learn the above through practice using a carefully chosen dataset.
Let’s load the dataset and dive in!
The Dataset
We’ll use the store_agents.csv for today’s tutorial. It contains data for the top sales agents for a department store.
The below code loads and prints the dataset using Pandas:
# Import Pandas library
import pandas as pd
# load the CSV file containing sales agents data
# First row is automatically set as the
# column labels / headers (blue)
#
# The first column has agent names (green). Set it as
# the row index using 'index_col' attribute
sales_agents = pd.read_csv('store_agents.csv', index_col=0)
sales_agents| Year | Category | Sales | Target_Met | Commission | Cust_Rating | |
|---|---|---|---|---|---|---|
| Name | ||||||
| Emily | 2021 | Beauty | 17890 | 100% | 1125 | 4.8 |
| Chris | 2021 | Clothing | 18060 | 92% | 950 | 4.9 |
| Maya | 2021 | Home | 20440 | 95% | 1000 | 4.7 |
| Bobby | 2021 | Pets | 18840 | 78% | 900 | 4.3 |
| Isabella | 2021 | Toys | 20560 | 87% | 1075 | 4.6 |
| Ajay | 2022 | Beauty | 21460 | 95% | 1175 | 4.8 |
| Donna | 2022 | Clothing | 20140 | 94% | 975 | 4.4 |
| Maya | 2022 | Home | 21310 | 85% | 940 | 4.6 |
| Priya | 2022 | Pets | 21610 | 100% | 960 | 4.9 |
| Tyler | 2022 | Toys | 19180 | 90% | 1005 | 4.7 |
As you can see, the dataset consists of top sales agents for different sales categories. There are a total of 10 entries, with 5 for each year, 2021 and 2022.
Label and Position-based Indexes
Label Indexes
Notice that we’ve set the first column (sales agent names) as the row index (in green). Similarly, the first row is set as the column index or headers (in blue).
These indexes help us identify a row or column using convenient string labels.
For example, if you want to look at the data for a specific sales agent, let’s say Isabella, you can check the row labeled Isabella.
Similarly, you can get the commission earned by all the sales agents using the column labeled Commission.
You can print the row label index using DataFrame attribute index:
# print row label index
sales_agents.indexIndex(['Emily', 'Chris', 'Maya', 'Bobby', 'Isabella', 'Ajay',
'Donna', 'Maya', Priya', 'Tyler'],
dtype='object', name='Name')And the column label index using the attribute columns:
# print column label index
sales_agents.columnsIndex(['Year', 'Category', 'Sales', 'Target_Met', 'Commission',
'Cust_Rating'], dtype='object')Position-based Indexes
The label indexes we discussed above work great - they give you an easy way to identify rows or columns using text labels.
There’s another type of index that’s not so obvious when you print a DataFrame.
When creating a DataFrame, Pandas assigns an integer reference to each row or column. These references are position-based - the first entry gets the integer value 0, the second entry gets 1, and so on.
The below image shows both types of indexes - the explicit, label-based and the implicit, position-based:
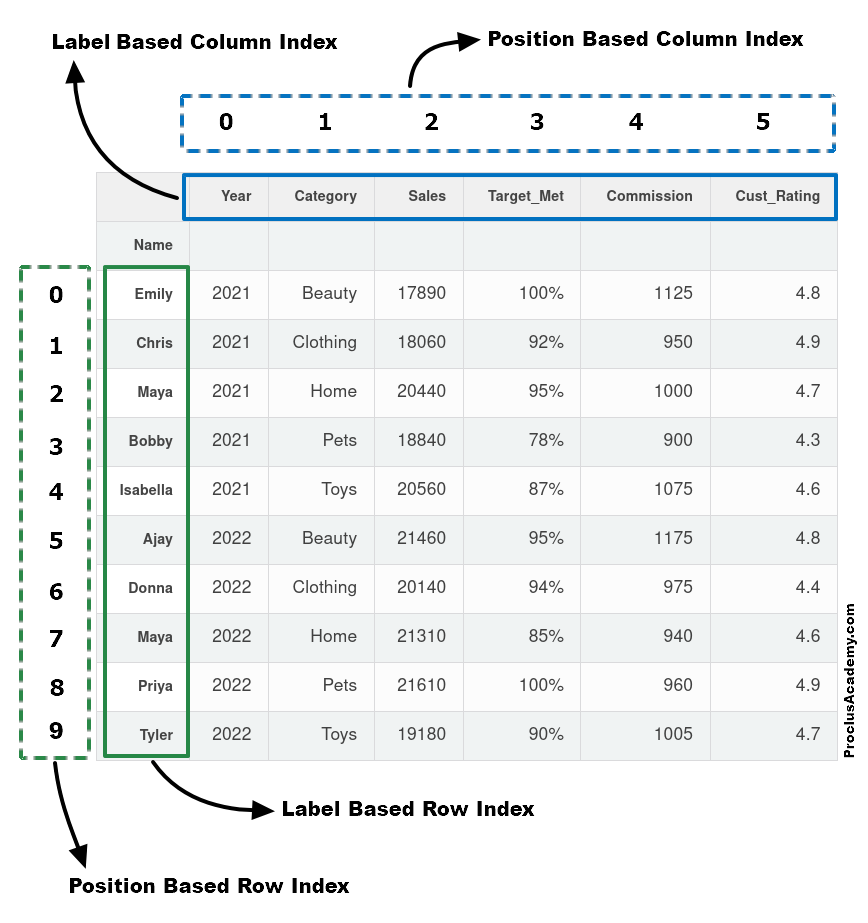
You can use either type of index to fetch data from a DataFrame.
For example, I mentioned earlier that you can access data for Isabella using the labeled row index that matches her first name. You can also get the same row of data using the corresponding position-based row index (number 4).
Now that you know there are two types of indexes, how do you use them to access DataFrame data?
Read on to find out!
Introducing iloc[] and loc[]
Pandas DataFrame provides two methods to select data using the row and column indexes - iloc[] and loc[]. Let’s look at them closely.
You can use iloc[] to fetch data using the integer or position-based indexes. And loc[] to select data using the label indexes:
iloc[Position-based Row Indexes, Position-based Column Indexes]
loc[Labeled Row Indexes, Labeled Column Indexes]
The second parameter (column indexes) is optional. If it’s missing, both methods will return all the columns for the rows selected based on the input row indexes.
Let’s see some practical examples. That’ll make these (somewhat theoretical) concepts crystal clear to you.
Selecting Rows
In this section, I’ll show you all the ways to select rows using both methods - iloc[] and loc[].
A Single Row
Suppose you want to select only one row, specifically the first row. You can use iloc[] with the row’s position-based index (0):
# Get the first row using the position index.
sales_agents.iloc[0]Year 2021
Category Beauty
Sales 17890
Target_Met 100%
Commission 1125
Cust_Rating 4.8
Name: Emily, dtype: objectThe label index for the first row is Emily. You can use it with loc[] to get the same row data:2
# Get the first row using the label index.
sales_agents.loc['Emily']Year 2021
Category Beauty
Sales 17890
Target_Met 100%
Commission 1125
Cust_Rating 4.8
Name: Emily, dtype: objectA List of Rows
Let’s say you want to fetch the data for three specific sales agents - Chris, Bobby, and Ajay.
Remember that we used the agent names as the label indexes. Therefore, we can pass specific names as a list to loc[] to get the relevant rows:
# Pass a list of index labels to loc[]
# to get rows corresponding to those indexes
sales_agents.loc[['Chris', 'Bobby', 'Ajay']]| Year | Category | Sales | Target_Met | Commission | Cust_Rating | |
|---|---|---|---|---|---|---|
| Name | ||||||
| Chris | 2021 | Clothing | 18060 | 92% | 950 | 4.9 |
| Bobby | 2021 | Pets | 18840 | 78% | 900 | 4.3 |
| Ajay | 2022 | Beauty | 21460 | 95% | 1175 | 4.8 |
You can also get the same data using iloc[]. To do that, you’ll need to get the position-based indexes for Chris, Bobby, and Ajay. It’ll be 1, 3, and 5 as we saw above.
Let’s pass these numeric indexes as a list to iloc[]:
# Get the same data as above using the
# corresponding position-based indexes
sales_agents.iloc[[1, 3, 5]]| Year | Category | Sales | Target_Met | Commission | Cust_Rating | |
|---|---|---|---|---|---|---|
| Name | ||||||
| Chris | 2021 | Clothing | 18060 | 92% | 950 | 4.9 |
| Bobby | 2021 | Pets | 18840 | 78% | 900 | 4.3 |
| Ajay | 2022 | Beauty | 21460 | 95% | 1175 | 4.8 |
As expected, we fetched exactly the same rows as the previous loc[] call.
First ‘N’ Rows
You can get the first ‘N’ rows of a DataFrame using the slice notation. Let’s see examples of this using both iloc[] and loc[].
Using iloc[]
Suppose you want to see only the first four rows. Remember that the position-based indexing starts with 0. Therefore, you want to load the rows with index values 0, 1, 2 & 3.
You can do that using iloc[] with the input slice :4.
Why end with 4? That’s because iloc[] excludes the end index. So iloc[:4] will return the rows with numeric indexes 0, 1, 2 & 3:
# Get the first four rows using iloc[]
# We passed ":4" as input
# Since there's nothing before colon(:), iloc will start
# at the beginning of the DataFrame.
# The ending index is exclusive. So iloc will stop at
# the position index before 4.
# Effectively, it'll fetch rows with index 0 to 3
sales_agents.iloc[:4]| Year | Category | Sales | Target_Met | Commission | Cust_Rating | |
|---|---|---|---|---|---|---|
| Name | ||||||
| Emily | 2021 | Beauty | 17890 | 100% | 1125 | 4.8 |
| Chris | 2021 | Clothing | 18060 | 92% | 950 | 4.9 |
| Maya | 2021 | Home | 20440 | 95% | 1000 | 4.7 |
| Bobby | 2021 | Pets | 18840 | 78% | 900 | 4.3 |
Using loc[]
How do you get the same result as above (the first four rows) using the label index?
We know that the label index for the fourth row is Bobby. The loc[] method includes the end index of a slice (unlike iloc[]). Therefore, iloc[:‘Bobby’] will get us the first four rows:
# Get the first four rows using loc[]
# We passed ":'Bobby'" as input
# Since there's nothing before colon(:), loc will start
# at the beginning of the DataFrame.
# The ending index is inclusive. So loc will stop at
# the label index 'Bobby'.
sales_agents.loc[:'Bobby']| Year | Category | Sales | Target_Met | Commission | Cust_Rating | |
|---|---|---|---|---|---|---|
| Name | ||||||
| Emily | 2021 | Beauty | 17890 | 100% | 1125 | 4.8 |
| Chris | 2021 | Clothing | 18060 | 92% | 950 | 4.9 |
| Maya | 2021 | Home | 20440 | 95% | 1000 | 4.7 |
| Bobby | 2021 | Pets | 18840 | 78% | 900 | 4.3 |
Last ‘N’ Rows
You can fetch the last ‘N’ rows of a DataFrame using slices with a negative index. Let’s see examples using both iloc[] and loc[].
Using iloc[]
Let’s say you want to get only the last four rows. You can do that using the input slice iloc[-4:].
# Get the last four rows using iloc[]
# We passed "-4:" as input
# The -4 before the colon(:) means iloc will start
# at the fourth row from the bottom.
# The ending index is empty (nothing after :).
# So iloc will include all the rows until the end
sales_agents.iloc[-4:]| Year | Category | Sales | Target_Met | Commission | Cust_Rating | |
|---|---|---|---|---|---|---|
| Name | ||||||
| Donna | 2022 | Clothing | 20140 | 94% | 975 | 4.4 |
| Maya | 2022 | Home | 21310 | 85% | 940 | 4.6 |
| Priya | 2022 | Pets | 21610 | 100% | 960 | 4.9 |
| Tyler | 2022 | Toys | 19180 | 90% | 1005 | 4.7 |
Using loc[]
You can use loc[] and label row index to get the same result as above.
The label index for the fourth row from the bottom is Donna. So loc[‘Donna’:] will fetch the last four rows:
# Get the last four rows using loc[]
# We passed 'Donna': as input
# So loc[] starts with the row with index 'Donna'
# and includes all the rows after it
sales_agents.loc['Donna':]| Year | Category | Sales | Target_Met | Commission | Cust_Rating | |
|---|---|---|---|---|---|---|
| Name | ||||||
| Donna | 2022 | Clothing | 20140 | 94% | 975 | 4.4 |
| Maya | 2022 | Home | 21310 | 85% | 940 | 4.6 |
| Priya | 2022 | Pets | 21610 | 100% | 960 | 4.9 |
| Tyler | 2022 | Toys | 19180 | 90% | 1005 | 4.7 |
A consecutive ‘Slice’ of Rows
You can access a block of consecutive rows from the middle of the DataFrame. Let me show you how to do that using loc[] and iloc[].
Using loc[]
Suppose you want to fetch all the rows from Isabella to Priya. You can do so using loc[] with these labels as the starting and ending slice indexes:
# Get consecutive rows starting with 'Isabella'
# and ending with 'Priya' (both inclusive)
sales_agents.loc['Isabella':'Priya']| Year | Category | Sales | Target_Met | Commission | Cust_Rating | |
|---|---|---|---|---|---|---|
| Name | ||||||
| Isabella | 2021 | Toys | 20560 | 87% | 1075 | 4.6 |
| Ajay | 2022 | Beauty | 21460 | 95% | 1175 | 4.8 |
| Donna | 2022 | Clothing | 20140 | 94% | 975 | 4.4 |
| Maya | 2022 | Home | 21310 | 85% | 940 | 4.6 |
| Priya | 2022 | Pets | 21610 | 100% | 960 | 4.9 |
Using iloc[]
You can also use iloc[] to get all the rows from Isabella to Priya. First, we need to get their position-based indexes, as iloc[] only works with such indexes.
As per the figure above, the position-based indexes for Isabella and Priya are 4 and 8, respectively.
However, recall that iloc[] excludes the ending index of a slice. Therefore, we’ll need to request the rows from index 4 to 9:
# Get a block of consecutive rows using iloc[]
# inclusive:exclusive - row with the ending index is excluded
sales_agents.iloc[4:9]| Year | Category | Sales | Target_Met | Commission | Cust_Rating | |
|---|---|---|---|---|---|---|
| Name | ||||||
| Isabella | 2021 | Toys | 20560 | 87% | 1075 | 4.6 |
| Ajay | 2022 | Beauty | 21460 | 95% | 1175 | 4.8 |
| Donna | 2022 | Clothing | 20140 | 94% | 975 | 4.4 |
| Maya | 2022 | Home | 21310 | 85% | 940 | 4.6 |
| Priya | 2022 | Pets | 21610 | 100% | 960 | 4.9 |
Fetch All Rows
You can access all the rows of a DataFrame using just the colon (:) with loc[] or iloc[]:
# Get all the rows
sales_agents.iloc[:]
# Below loc[] will get the same data as well
# sales_agents.loc[:]| Year | Category | Sales | Target_Met | Commission | Cust_Rating | |
|---|---|---|---|---|---|---|
| Name | ||||||
| Emily | 2021 | Beauty | 17890 | 100% | 1125 | 4.8 |
| Chris | 2021 | Clothing | 18060 | 92% | 950 | 4.9 |
| Maya | 2021 | Home | 20440 | 95% | 1000 | 4.7 |
| Bobby | 2021 | Pets | 18840 | 78% | 900 | 4.3 |
| Isabella | 2021 | Toys | 20560 | 87% | 1075 | 4.6 |
| Ajay | 2022 | Beauty | 21460 | 95% | 1175 | 4.8 |
| Donna | 2022 | Clothing | 20140 | 94% | 975 | 4.4 |
| Maya | 2022 | Home | 21310 | 85% | 940 | 4.6 |
| Priya | 2022 | Pets | 21610 | 100% | 960 | 4.9 |
| Tyler | 2022 | Toys | 19180 | 90% | 1005 | 4.7 |
Index with Duplicate Labels
You might have noticed that we have two rows with the same index label. That’s because Donna was one of the top agents for 2001 and 2002.
I’ve highlighted the two rows with the duplicate index label. Note that these rows are not consecutive - there are other rows between them:
| Year | Category | Sales | Target_Met | Commission | Cust_Rating | |
|---|---|---|---|---|---|---|
| Name | ||||||
| Emily | 2021 | Beauty | 17890 | 100% | 1125 | 4.8 |
| Chris | 2021 | Clothing | 18060 | 92% | 950 | 4.9 |
| Maya | 2021 | Home | 20440 | 95% | 1000 | 4.7 |
| Bobby | 2021 | Pets | 18840 | 78% | 900 | 4.3 |
| Isabella | 2021 | Toys | 20560 | 87% | 1075 | 4.6 |
| Ajay | 2022 | Beauty | 21460 | 95% | 1175 | 4.8 |
| Donna | 2022 | Clothing | 20140 | 94% | 975 | 4.4 |
| Maya | 2022 | Home | 21310 | 85% | 940 | 4.6 |
| Priya | 2022 | Pets | 21610 | 100% | 960 | 4.9 |
| Tyler | 2022 | Toys | 19180 | 90% | 1005 | 4.7 |
The loc[] method behaves erratically with such duplicate labels as the input. Sometimes, it’ll fetch the data. At other times, it’ll throw an error.
Let’s take a closer look at this unpredictable behavior. And discuss the reasons why loc[] acts this way.
The Problem: Duplicate Label & loc[]
When we use loc[] with the duplicate index label Maya, we expect it to return both highlighted rows. That’s exactly what it does:
# loc[] returns all rows with duplicate index label
# This is expected. No surprises here
sales_agents.loc['Maya']| Year | Category | Sales | Target_Met | Commission | Cust_Rating | |
|---|---|---|---|---|---|---|
| Name | ||||||
| Maya | 2021 | Home | 20440 | 95% | 1000 | 4.7 |
| Maya | 2022 | Home | 21310 | 85% | 940 | 4.6 |
However, loc[] will throw an error when you try to slice a DataFrame using the duplicate label as the starting or ending index.
For example, the below code should return all the rows from Emily to Maya. Instead, we get an error:
sales_agents.loc['Emily':'Maya']Error: KeyError: ”Cannot get right slice bound for non-unique label: ‘Maya’”.
Why does loc[] behave this way?
There are two rows with the same index, Maya. That throws loc[] off. It doesn’t know which one of the duplicate labels it should use as the ending row.
The loc[] will throw a similar error if you use the duplicate label as the starting index:
sales_agents.loc['Maya':]Error: KeyError: ”Cannot get left slice bound for non-unique label: ‘Maya’”.
The Fix: Sort the DataFrame by Label Index
Recall that the two rows with the duplicate label Maya are not consecutive. That’s the root cause of the problems with loc[] we saw in the previous section.
When asked to retrieve a slice with Maya as the starting or ending index, loc[] doesn’t know which of the two rows to use. Hence, it throws the KeyError.
You can fix this issue by sorting the DataFrame by the index. Let’s see it in action.
First, we sort the DataFrame using the sort_index() method:
# Sort the DataFrame by the index
# Store the result in another variable
agents_sorted = sales_agents.sort_index()
agents_sorted| Year | Category | Sales | Target_Met | Commission | Cust_Rating | |
|---|---|---|---|---|---|---|
| Name | ||||||
| Ajay | 2022 | Beauty | 21460 | 95% | 1175 | 4.8 |
| Bobby | 2021 | Pets | 18840 | 78% | 900 | 4.3 |
| Chris | 2021 | Clothing | 18060 | 92% | 950 | 4.9 |
| Donna | 2022 | Clothing | 20140 | 94% | 975 | 4.4 |
| Emily | 2021 | Beauty | 17890 | 100% | 1125 | 4.8 |
| Isabella | 2021 | Toys | 20560 | 87% | 1075 | 4.6 |
| Maya | 2021 | Home | 20440 | 95% | 1000 | 4.7 |
| Maya | 2022 | Home | 21310 | 85% | 940 | 4.6 |
| Priya | 2022 | Pets | 21610 | 100% | 960 | 4.9 |
| Tyler | 2022 | Toys | 19180 | 90% | 1005 | 4.7 |
After sorting, the two rows with the duplicate label appear next to each other. See the rows highlighted above.
Now, you can use loc[] with the duplicate label as the starting or ending index of a slice. It won’t throw any error and will return the expected data:
# loc[] - Get a slice of data ending with
# a duplicate label
agents_sorted.loc['Emily':'Maya']| Year | Category | Sales | Target_Met | Commission | Cust_Rating | |
|---|---|---|---|---|---|---|
| Name | ||||||
| Emily | 2021 | Beauty | 17890 | 100% | 1125 | 4.8 |
| Isabella | 2021 | Toys | 20560 | 87% | 1075 | 4.6 |
| Maya | 2021 | Home | 20440 | 95% | 1000 | 4.7 |
| Maya | 2022 | Home | 21310 | 85% | 940 | 4.6 |
# loc[] - Get a slice of data starting with
# a duplicate label
agents_sorted.loc['Maya':]| Year | Category | Sales | Target_Met | Commission | Cust_Rating | |
|---|---|---|---|---|---|---|
| Name | ||||||
| Maya | 2021 | Home | 20440 | 95% | 1000 | 4.7 |
| Maya | 2022 | Home | 21310 | 85% | 940 | 4.6 |
| Priya | 2022 | Pets | 21610 | 100% | 960 | 4.9 |
| Tyler | 2022 | Toys | 19180 | 90% | 1005 | 4.7 |
Top Agents For 2021
We’ll use a smaller subset of the DataFrame sales_agents for the rest of the article. Let’s select the first five rows using iloc[] and save them as a new DataFrame agents_2021:
# Select first 5 rows
agents_2021 = sales_agents.iloc[:5]
agents_2021| Year | Category | Sales | Target_Met | Commission | Cust_Rating | |
|---|---|---|---|---|---|---|
| Name | ||||||
| Emily | 2021 | Beauty | 17890 | 100% | 1125 | 4.8 |
| Chris | 2021 | Clothing | 18060 | 92% | 950 | 4.9 |
| Maya | 2021 | Home | 20440 | 95% | 1000 | 4.7 |
| Bobby | 2021 | Pets | 18840 | 78% | 900 | 4.3 |
| Isabella | 2021 | Toys | 20560 | 87% | 1075 | 4.6 |
We’ll use this smaller dataset, agents_2021, for the next section.
Selecting Columns
Recall that you can use iloc[] and loc[] to access DataFrame data using the row and column index as the inputs:
iloc[Position-based Row Indexes, Position-based Column Indexes]
loc[Labeled Row Indexes, Labeled Column Indexes]
So far, we covered a variety of ways of slicing the rows using the row indexes.
Now, let’s focus on the second parameter - the column indexes.
I’ll show you how to slice columns using the position-based column index with iloc[]. You’ll also learn how to use label column index with loc[] to fetch the desired columns.
Note: Since we’ll work on the column indexes, we won’t do any row filtering in this section. We’ll set the row index to colon (:) to fetch all the rows.
A Single Column
Suppose you want to select only one column, specifically the Sales column. You can use loc[] with the column label index:
# Select only one column for all the rows
# Use loc[] along with the column's label index ('Sales')
agents_2021.loc[:, 'Sales']Name
Emily 17890
Chris 18060
Maya 20440
Bobby 18840
Isabella 20560
Name: Sales, dtype: int64We can get the same data using iloc[] as well. The position-based index for the column Sales is 2. Let’s pass that to the iloc[] method:
# Select only one column - 'Sales'
# Use iloc[] along with the column's position-based index
agents_2021.iloc[:, 2]Name
Emily 17890
Chris 18060
Maya 20440
Bobby 18840
Isabella 20560
Name: Sales, dtype: int64A List of Columns
Suppose you want to fetch the data for three columns - Year, Sales, and Commission. We can pass these column labels as a list to loc[]:
# Get data for a list of columns using loc[]
# Pass the list of column labels as the input
agents_2021.loc[:, ['Year', 'Sales', 'Commission']]| Year | Sales | Commission | |
|---|---|---|---|
| Name | |||
| Emily | 2021 | 17890 | 1125 |
| Chris | 2021 | 18060 | 950 |
| Maya | 2021 | 20440 | 1000 |
| Bobby | 2021 | 18840 | 900 |
| Isabella | 2021 | 20560 | 1075 |
You can also access the same data using iloc[]. You’ll need to get the position-based indexes for the columns Year, Sales, and Commission. It’ll be 0, 2, and 4, as we saw above.
Let’s pass these numeric column indexes as a list to iloc[]:
# Get data for a list of columns using iloc[]
# Pass the list of position-based column indexes
# as the input
agents_2021.iloc[:, [0, 2, 4]]| Year | Sales | Commission | |
|---|---|---|---|
| Name | |||
| Emily | 2021 | 17890 | 1125 |
| Chris | 2021 | 18060 | 950 |
| Maya | 2021 | 20440 | 1000 |
| Bobby | 2021 | 18840 | 900 |
| Isabella | 2021 | 20560 | 1075 |
First ‘N’ Columns
Recall that we selected the first ‘N’ rows using the slice notation. We’ll also apply a similar approach to fetch the first ‘N’ columns.
Using iloc[]
Let’s say you want to get the first three columns. As discussed, the iloc[] method expects input slices to be end exclusive. Therefore, we’ll use the columns slice :3 to fetch the first three columns (with indexes 0, 1, & 2):
# iloc[] expects end exclusive slices
# So the column index slice :3 will fetch
# columns with index 0, 1, & 2
agents_2021.iloc[:, :3]| Year | Category | Sales | |
|---|---|---|---|
| Name | |||
| Emily | 2021 | Beauty | 17890 |
| Chris | 2021 | Clothing | 18060 |
| Maya | 2021 | Home | 20440 |
| Bobby | 2021 | Pets | 18840 |
| Isabella | 2021 | Toys | 20560 |
Using loc[]
We can also get the first three columns using loc[]. The label of the third column is Sales. So we’ll instruct loc[] to fetch all the columns from the beginning to Sales:
# Get columns - from the first column to the
# last column with label 'Sales'
# Unlike iloc[], loc[] treats slices as
# end inclusive. So it'll fetch 'Sales'
# column as well
agents_2021.loc[:, :'Sales']| Year | Category | Sales | |
|---|---|---|---|
| Name | |||
| Emily | 2021 | Beauty | 17890 |
| Chris | 2021 | Clothing | 18060 |
| Maya | 2021 | Home | 20440 |
| Bobby | 2021 | Pets | 18840 |
| Isabella | 2021 | Toys | 20560 |
Last ‘N’ Columns
We can get the last ‘N’ columns using the slices with a negative index. Let’s see this in action.
Using iloc
Suppose you want to get the last three columns. You can do that by using -3: as the column slice:
# Fetch the last three columns using iloc[]
agents_2021.iloc[:, -3:]| Target_Met | Commission | Cust_Rating | |
|---|---|---|---|
| Name | |||
| Emily | 100% | 1125 | 4.8 |
| Chris | 92% | 950 | 4.9 |
| Maya | 95% | 1000 | 4.7 |
| Bobby | 78% | 900 | 4.3 |
| Isabella | 87% | 1075 | 4.6 |
Using loc[]
You can get the same results as above using loc[] and the column label index.
The label index for the third last column is Target_Met. So we can use the slice Target_Met: with loc[].
# Get all the columns starting from the
# column 'Target_Met' to the end
# That'll get us the last three columns
agents_2021.loc[:, 'Target_Met':]| Target_Met | Commission | Cust_Rating | |
|---|---|---|---|
| Name | |||
| Emily | 100% | 1125 | 4.8 |
| Chris | 92% | 950 | 4.9 |
| Maya | 95% | 1000 | 4.7 |
| Bobby | 78% | 900 | 4.3 |
| Isabella | 87% | 1075 | 4.6 |
A Slice of Consecutive Columns
We just learned how to get the first or last N columns. You can go one step further. The methods loc[] and iloc[] allow you to fetch any block or slice of consecutive columns.
Let me show you how to do that.
Using loc[]
Suppose you want to access the columns from Category to Commission. We can create a slice with these columns as the starting and ending indexes. And then invoke loc[] using that slice:
# Get columns from 'Category' to 'Commission' (Both included)
agents_2021.loc[:, 'Category':'Commission']| Category | Sales | Target_Met | Commission | |
|---|---|---|---|---|
| Name | ||||
| Emily | Beauty | 17890 | 100% | 1125 |
| Chris | Clothing | 18060 | 92% | 950 |
| Maya | Home | 20440 | 95% | 1000 |
| Bobby | Pets | 18840 | 78% | 900 |
| Isabella | Toys | 20560 | 87% | 1075 |
Using iloc[]
You can also use iloc[] to get a slice of consecutive columns.
Suppose we want the same result as above (the columns from Category to Commission). We’ll need to find the position-based indexes for these columns. That’ll be 1 and 4, as per the figure above.
We’ll use indexes to create a slice of columns. However, remember that input slices to iloc[] are end exclusive. Therefore, we’ll need to use 5 as the slice end index:
# Input slices to iloc are end exclusive
# Hence, use 1:5 to get columns 1, 2, 3, and 4.
agents_2021.iloc[:, 1:5]| Category | Sales | Target_Met | Commission | |
|---|---|---|---|---|
| Name | ||||
| Emily | Beauty | 17890 | 100% | 1125 |
| Chris | Clothing | 18060 | 92% | 950 |
| Maya | Home | 20440 | 95% | 1000 |
| Bobby | Pets | 18840 | 78% | 900 |
| Isabella | Toys | 20560 | 87% | 1075 |
Combining Row and Column Selectors
So far, we’ve learned how to access either rows or columns of a DataFrame in isolation.
We can combine the row and column selection in the same iloc[] or loc[] call. Remember that these methods expect two parameters - row indexes and column indexes:
iloc[Position-based Row Indexes, Position-based Column Indexes]
loc[Labeled Row Indexes, Labeled Column Indexes]
You can pass the row and column indexes in any of the forms we’ve covered today - a single index, a list of indexes, and index slices.
Moreover, you can mix and match the row and column forms. For example, the first parameter could be a single row index, and the second parameter could be an index slice.
Let’s see some examples.
loc[]: Specific Rows and Slice of Columns
Suppose you want to fetch the columns from Sales to Cust_Rating for 3 agents - Ajay, Bobby, and Isabella.
Below loc[] call passes the agent names as a list of row labels and a slice of column labels. That’ll get us the results we want:
# loc[] - Select specific rows and a range / slice of columns
# First argument - list of row labels
# Second argument - slice of columns
sales_agents.loc[['Ajay', 'Bobby', 'Isabella'], 'Sales':'Cust_Rating']| Sales | Target_Met | Commission | Cust_Rating | |
|---|---|---|---|---|
| Name | ||||
| Ajay | 21460 | 95% | 1175 | 4.8 |
| Bobby | 18840 | 78% | 900 | 4.3 |
| Isabella | 20560 | 87% | 1075 | 4.6 |
iloc[]: Slice of Rows and List of Columns
Below iloc[] call uses the position-based indexes to get a slice of rows and a list of columns.
Remember that slice ranges in iloc[] are end exclusive. Therefore, the rows slice 2:8 will fetch the rows with index 2 to 7.
# iloc[] - A range / slice of rows and list of columns
# First argument - a slice of integer rows indexes (end exclusive)
# Second argument - list of integer column indexes
sales_agents.iloc[2:8, [0, 1, 2, 4]]| Year | Category | Sales | Commission | |
|---|---|---|---|---|
| Name | ||||
| Maya | 2021 | Home | 20440 | 1000 |
| Bobby | 2021 | Pets | 18840 | 900 |
| Isabella | 2021 | Toys | 20560 | 1075 |
| Ajay | 2022 | Beauty | 21460 | 1175 |
| Donna | 2022 | Clothing | 20140 | 975 |
| Maya | 2022 | Home | 21310 | 940 |
iloc[]: Rows in Reverse With Limited Columns
Suppose you want to access rows bottom up - start with the last row, then show the second last row, and so on. Moreover, pull only the last three columns for all the rows.
Below iloc[] call does that for us. The first parameter ::-1 reverses the order of the rows. The second parameter -3: fetches only the last 3 columns:
# iloc[] - Fetch rows in reverse.
# Also, get only the last 3 columns
# First argument - get rows from bottom to top
# Second argument - show the last 3 columns
sales_agents.iloc[::-1, -3:]| Target_Met | Commission | Cust_Rating | |
|---|---|---|---|
| Name | |||
| Tyler | 90% | 1005 | 4.7 |
| Priya | 100% | 960 | 4.9 |
| Maya | 85% | 940 | 4.6 |
| Donna | 94% | 975 | 4.4 |
| Ajay | 95% | 1175 | 4.8 |
| Isabella | 87% | 1075 | 4.6 |
| Bobby | 78% | 900 | 4.3 |
| Maya | 95% | 1000 | 4.7 |
| Chris | 92% | 950 | 4.9 |
| Emily | 100% | 1125 | 4.8 |
As mentioned before, you can use iloc[] and loc[] with a single index, a list or a slice of indexes. You can mix and match any kind of row input with any type of column input. The possibilities are practically endless!
Summary
We covered a lot of ground today. Let’s recap the theoretical concepts and the invaluable practical skills you gained today:
- Pandas’ DataFrames have two types of indexes - the integer, position-based index and the label index.
- Both types of indexes are available for rows and columns of any DataFrame.
- You can use the below methods to access DataFrame rows and/or columns:
- iloc[] with position-based indexes.
- loc[] with the label indexes.
- These methods work with different types of inputs:
- a specific index value
- a list of (even non-continuous) index values
- a slice of index values
- Most importantly, this article showed you numerous practical examples of iloc[] and loc[] with various types of inputs.
That’s it for today. Ciao, until next time!
Footnotes
-
Technically iloc[] and loc[] are DataFrame properties. But you can think of them as special methods for all practical purposes. You invoke them using the square brackets, [], instead of the standard parentheses, (). ↩
-
If the result of an iloc[] or loc[] query is a single row, they’ll return a Pandas Series (instead of DataFrame). You can force it to return a DataFrame using the to_frame() method. Ex. sales_agents.iloc[0].to_frame() ↩
Title Image by
Martin Vorel