How can you perform K-Fold Cross-Validation to evaluate machine learning models?
I'll show you two ways using Python and Scikit-Learn's helper functions - cross_val_score() and cross_validate().

It's time to learn Cross-Validation, the tool serious data scientists use to estimate model performance.
Cross-Validation builds upon Train Test Split and provides a better estimate of a machine learning model's performance.

Sometimes you want to draw boxplots where each column gets its own y-axis.
Here's how you can do it using pandas, Matplotlib, and Seaborn.

Outliers can overshadow other data points of a feature. That can negatively influence standard scaling.
Here's why you should use robust scaling to handle outliers.

Sometimes the default statistics provided by pandas describe() method are not enough.
Here's how you can generate custom statistics using the agg() method.

Features with vastly different scales can lead to subpar machine learning models.
We must scale such features. Here’s how sklearn's Standard and MinMax scalers can help.

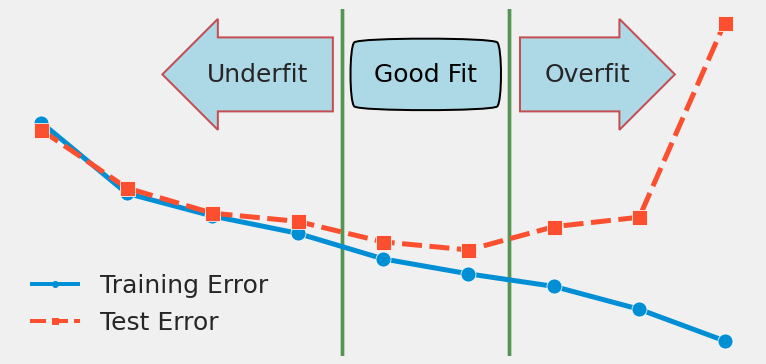
Overfitted machine learning models can lead to serious performance issues in the real world.
Let's explore how you can stop overfitting dead in it's tracks and train your models with confidence.
How can you apply different transformations to different columns of your dataset?
We'll explore a few ways and discuss why using ColumnTransformer is the best approach.
